Pandas 数据结构 - DataFrame
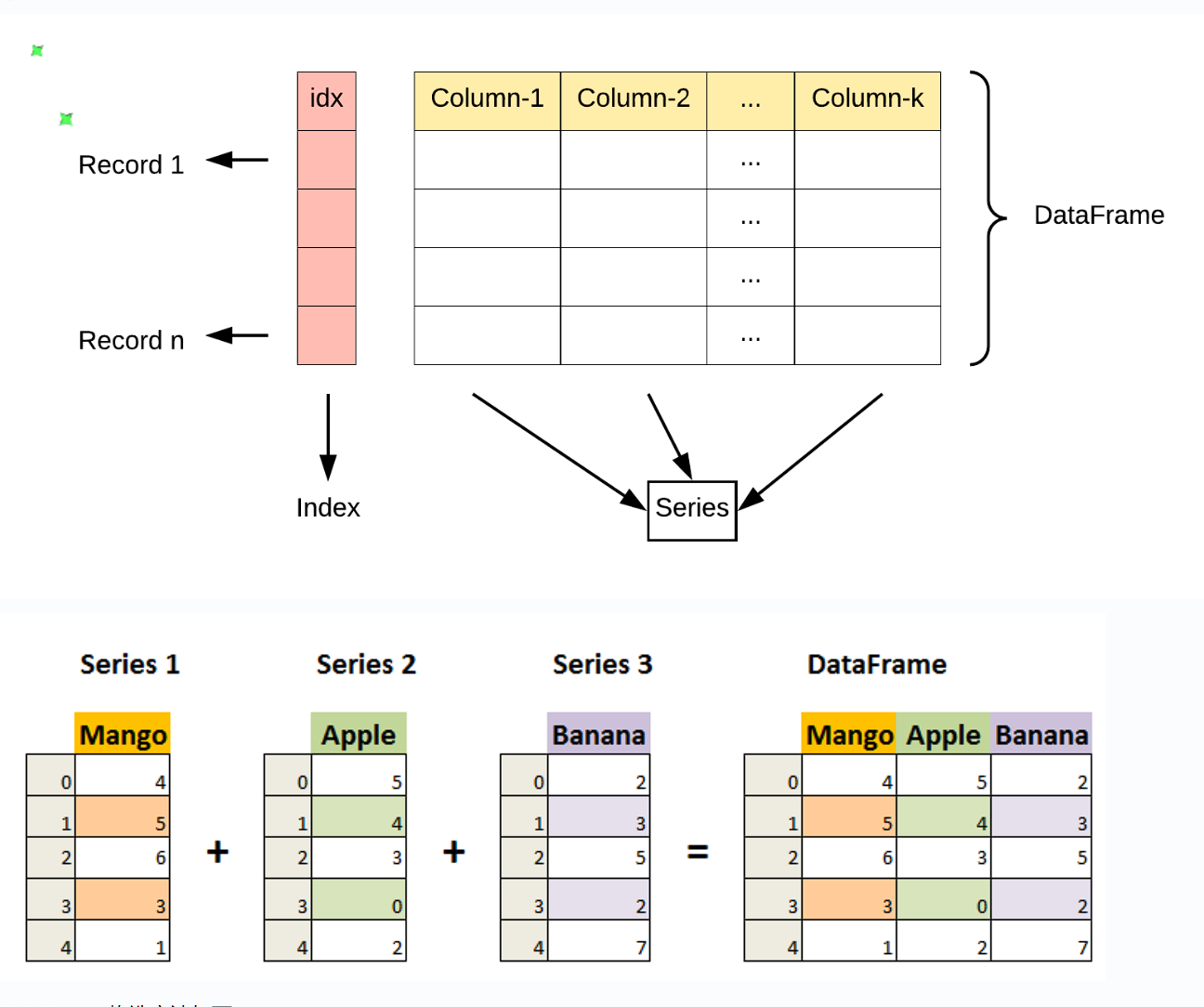
DataFrame 是 Pandas 中的另一个核心数据结构,类似于一个二维的表格或数据库中的数据表。
DataFrame 是一个表格型的数据结构,它含有一组有序的列,每列可以是不同的值类型(数值、字符串、布尔型值)。
DataFrame 既有行索引也有列索引,它可以被看做由 Series 组成的字典(共同用一个索引)。
DataFrame 提供了各种功能来进行数据访问、筛选、分割、合并、重塑、聚合以及转换等操作。
DataFrame 是一个非常灵活且强大的数据结构,广泛用于数据分析、清洗、转换、可视化等任务。
DataFrame 特点:
二维结构: DataFrame 是一个二维表格,可以被看作是一个 Excel 电子表格或 SQL 表,具有行和列。可以将其视为多个 Series 对象组成的字典。
列的数据类型: 不同的列可以包含不同的数据类型,例如整数、浮点数、字符串或 Python 对象等。
索引:DataFrame 可以拥有行索引和列索引,类似于 Excel 中的行号和列标。
大小可变:可以添加和删除列,类似于 Python 中的字典。
自动对齐:在进行算术运算或数据对齐操作时,DataFrame 会自动对齐索引。
处理缺失数据:DataFrame 可以包含缺失数据,Pandas 使用 NaN(Not a Number)来表示。
数据操作:支持数据切片、索引、子集分割等操作。
时间序列支持:DataFrame 对时间序列数据有特别的支持,可以轻松地进行时间数据的切片、索引和操作。
丰富的数据访问功能:通过 .loc、.iloc 和 .query() 方法,可以灵活地访问和筛选数据。
灵活的数据处理功能:包括数据合并、重塑、透视、分组和聚合等。
数据可视化:虽然 DataFrame 本身不是可视化工具,但它可以与 Matplotlib 或 Seaborn 等可视化库结合使用,进行数据可视化。
高效的数据输入输出:可以方便地读取和写入数据,支持多种格式,如 CSV、Excel、SQL 数据库和 HDF5 格式。
描述性统计:提供了一系列方法来计算描述性统计数据,如 .describe()、.mean()、.sum() 等。
灵活的数据对齐和集成:可以轻松地与其他 DataFrame 或 Series 对象进行合并、连接或更新操作。
转换功能:可以对数据集中的值进行转换,例如使用 .apply() 方法应用自定义函数。
滚动窗口和时间序列分析:支持对数据集进行滚动窗口统计和时间序列分析。
参数说明:
data:DataFrame 的数据部分,可以是字典、二维数组、Series、DataFrame 或其他可转换为 DataFrame 的对象。如果不提供此参数,则创建一个空的 DataFrame。
index:DataFrame 的行索引,用于标识每行数据。可以是列表、数组、索引对象等。如果不提供此参数,则创建一个默认的整数索引。
columns:DataFrame 的列索引,用于标识每列数据。可以是列表、数组、索引对象等。如果不提供此参数,则创建一个默认的整数索引。
dtype:指定 DataFrame 的数据类型。可以是 NumPy 的数据类型,例如 np.int64、np.float64 等。如果不提供此参数,则根据数据自动推断数据类型。
copy:是否复制数据。默认为 False,表示不复制数据。如果设置为 True,则复制输入的数据。
Pandas DataFrame 是一个二维的数组结构,类似二维数组。
Pandas 数据结构 - DataFrame
作者: xuetu11 | 发布时间: 2025-09-15 09:46 | 分类: 技术